三花快讯
一觉醒来看三花,分分钟 Get 全网 AI 动态
2025, 10月16日
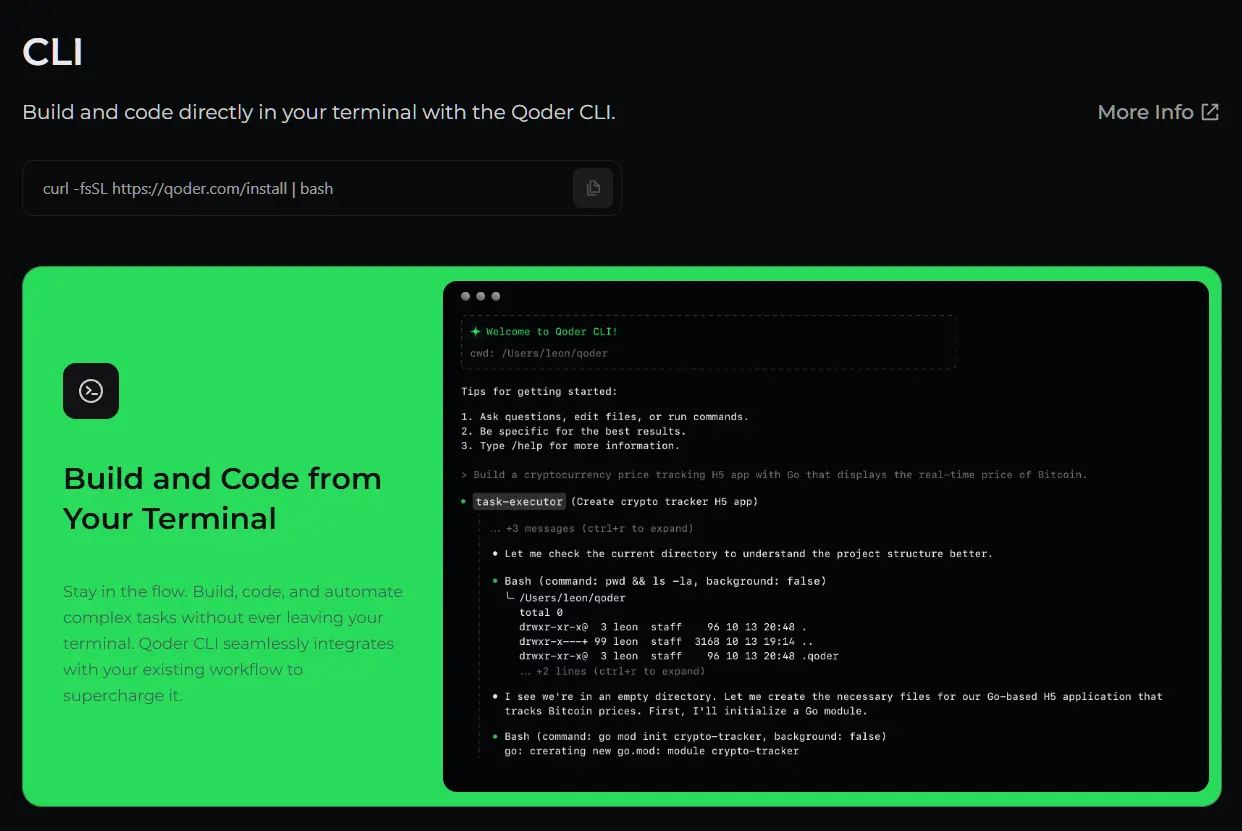
阿里 Qoder CLI 正式发布啦!这是阿里推出的又一个编程 Agent 命令行工具,搭载与IDE同款的多智能体编程引擎,支持在 Windows 与 macOS 上一键安装。
详细使用教程佬们可以看阿里 Qoder CLI 官网。
Google Veo 3.1 视频生成模型现已在Flow 平台上线,现已向 Gemini API、Vertex AI 与 Gemini 应用全面开放。
Veo 3.1 不仅能够生成自带音效的视频内容,其叙事控制能力也大幅提升,还能够生成逼真的纹理。
最良心的是,3.1 版本与 3.0 的 API 价格完全一致,加量不加价!
Anthropic发布了 Claude Haiku 4.5 ,这是 Claude 4.5 系列中体积最小、价格最低的模型。
官方宣称该模型能以三分之一的成本和两倍的速度,达到与 Sonnet 4 相当的编程能力。目前,GitHub Copilot、OpenRouter 等平台已同步上线该模型,佬们赶紧去体验一下!
2025, 10月15日
![]()
微软 AI 正式发布其首款完全自研的图像生成模型 MAI-Image-1,目前在 LMArena 竞技场上排名第九。
不过目前只能在 LMArena 上使用,官方表示后续会优先面向 Copilot 和 Bing Image Creator 中提供 MAI-Image-1 模型。
阿里 Qoder 官方命令行工具 Qoder CLI 即将正式发布!佬们可以去datawhale的微信公众号预约直播。
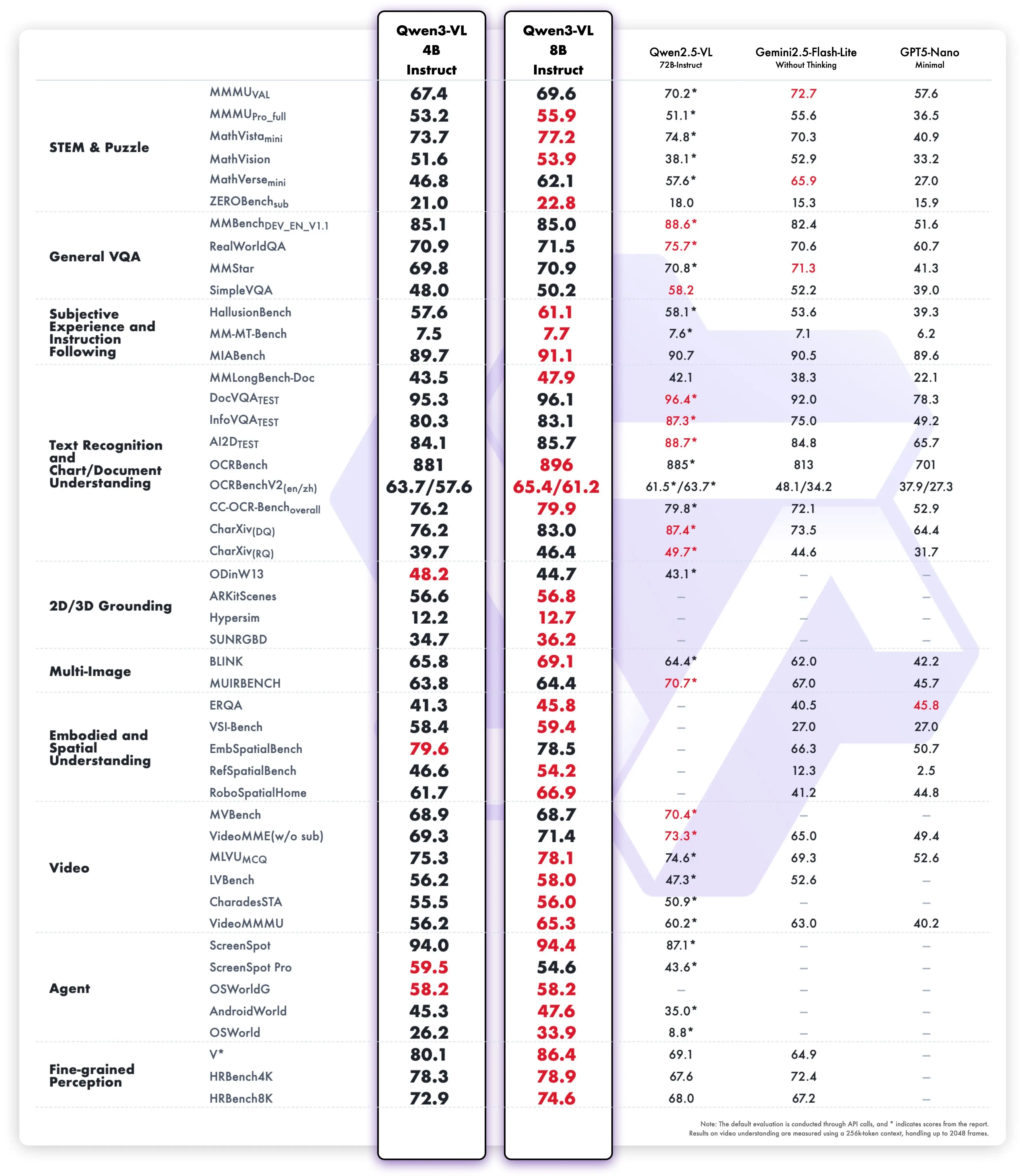
阿里通义开源了 Qwen3-VL 的 4B 和 8B 版本,显存占用更低的同时,完整保留了 Qwen3-VL 的核心功能。此外,还提供了 FP8 版本。
官方测试数据显示,在 STEM、VQA、OCR、视频理解以及 Agent 任务等多项测试中,居然超过了 Gemini 2.5 Flash Lite 和 GPT-5 Nano,有些表现甚至能媲美 Qwen2.5-VL-72B。
完整介绍佬们可以看通义的推文
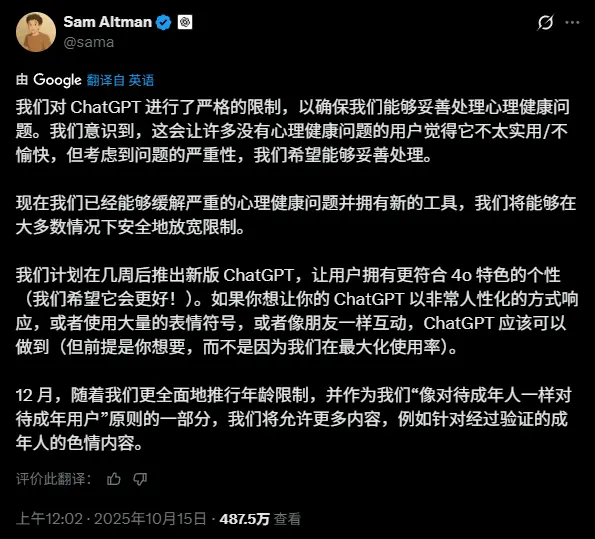
OpenAI CEO Sam Altman 在推特上宣布,未来几周将推出一个新版 GPT,类似 GPT-4o,回复更加人性化,就像你的朋友那样。
更劲爆的是,12 月将推出更全面的年龄限制,允许 GPT 在验证成年身份的情况下提供涩涩内容!好家伙,第一生产力来了。

马斯克发推表示 X 平台将于下月全面切换至由 Grok驱动的AI推荐系统,一并发布的还有模型权重的新算法。每天超过1亿条内容都将由 Grok 进行评估,并推荐最可能引起用户兴趣的内容,显著提升信息流的质量。
NotebookLM 视频概览功能发布更新升级 ,新增了六种由 Nano Banana 提供配图支持的视觉风格:Watercolor、Papercraft、Anime、Whiteboard、Retro Print 和 Heritage。
这次更新彻底告别了以往固定主体动态颜色的限制,效果提升明细。还没体验过的佬们快去试试吧!不过该功能目前仅支持 Pro 用户,谷歌官方表示未来将逐步覆盖全体用户。

Nanonets 发布并开源了 OCR 2 系列模型,包括 Nanonets-OCR2-Plus、Nanonets-OCR2-3B 与 Nanonets-OCR2-1.5B-exp 三个版本。该系列模型专注于将图像文档转换为结构化 Markdown,并支持视觉问答功能。
其背后是基于 Qwen2-VL 微调而来,3B 版本在超过 300 万页的混合文档上进行训练,覆盖了论文、财报、合同、病历、税表、收据、手写及多语种材料,有需要的佬可以看看。