DeepSeek 发布 236B 模型: DeepSeek-V2
DeepSeek 发布 236B 参数 160 位专家的专家混合(MoE)模型: DeepSeek-V2 ,经济的训练成本和高效的推理能力,完全开源。
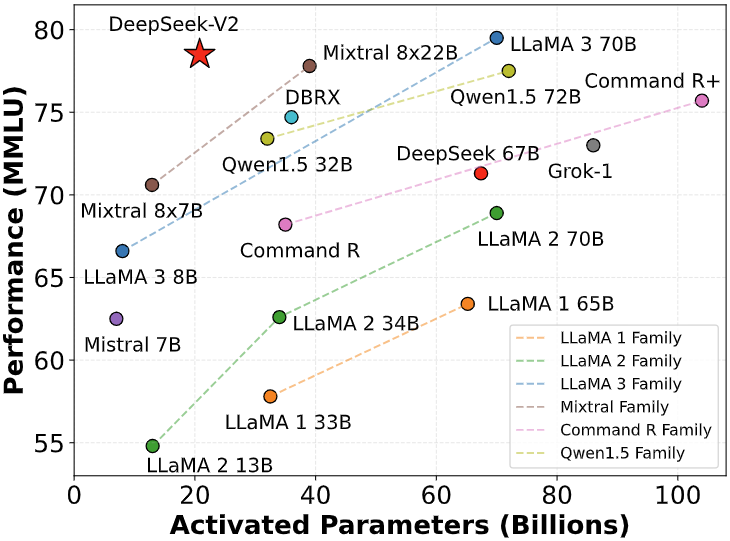
DeepSeek 发布 236B 参数 160 位专家的专家混合(MoE)模型: DeepSeek-V2 ,经济的训练成本和高效的推理能力,完全开源。
- 参数规模: 总参数量为236B,每个token激活21B参数。
- 性能对比: 与DeepSeek 67B相比,DeepSeek-V2性能更强,训练成本节约42.5%,KV缓存减少93.3%,最大生成吞吐量提升至5.76倍。
- 预训练数据: 使用8.1万亿token的高质量语料库进行预训练。
- 训练过程: 包括监督式微调(SFT)和强化学习(RL),以充分发挥模型潜力。
商业转载请联系三花微信公众号获得授权,非商业转载请注明本文出处及文章链接,您可以自由地在任何媒体以任何形式复制和分发作品,也可以修改和创作,但是分发衍生作品时必须采用相同的许可协议。
本文采用 CC BY-NC-SA 4.0 - 非商业性使用 - 相同方式共享 4.0 国际 进行许可。