三花快讯 · 2025, 7月16日
PUSA V1.0:低成本高性能视频生成模型
支持首尾帧生成和视频扩展等多项功能
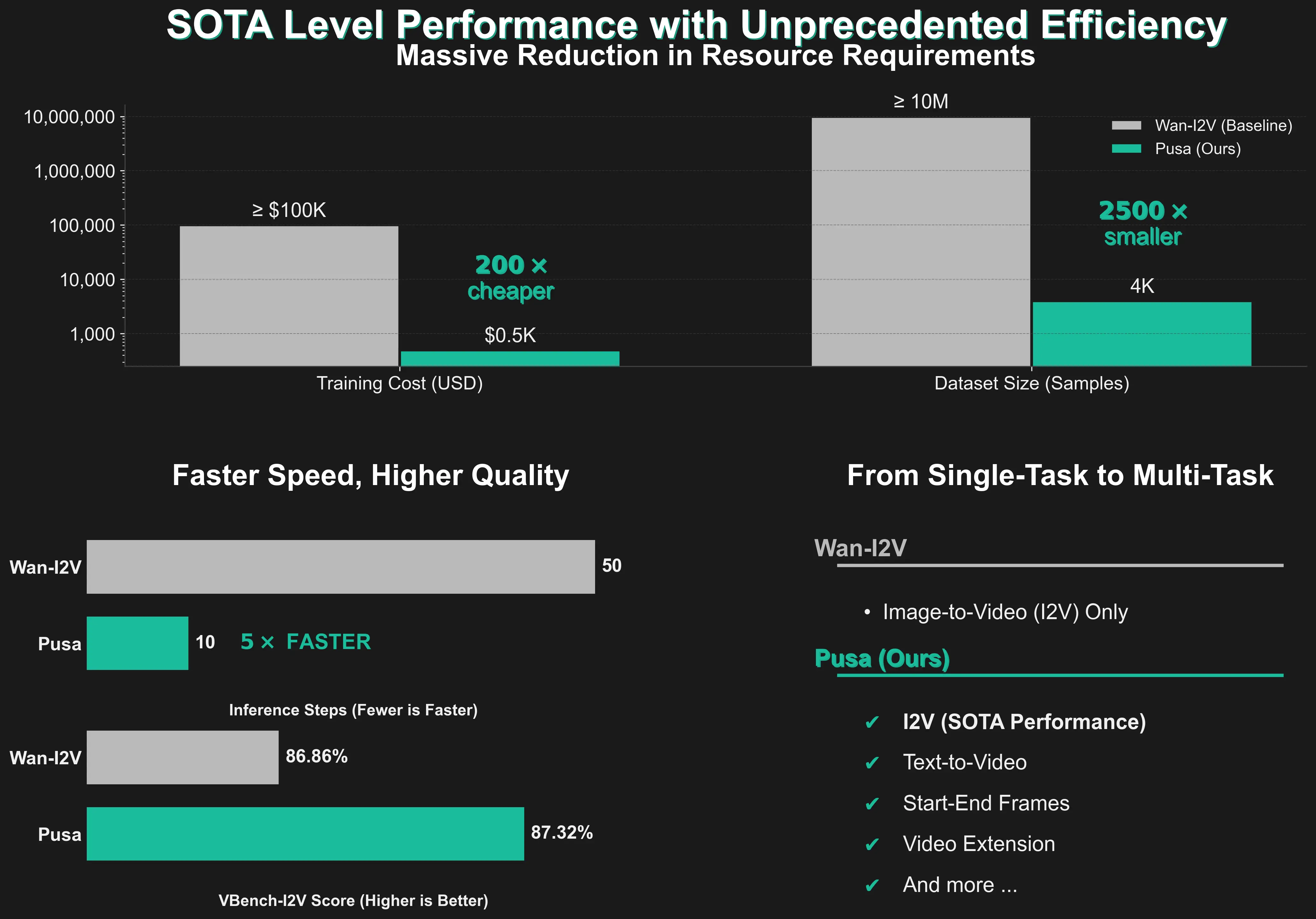
PUSA V1.0 通过使用 VTA 微调 SOTA 模型 Wan2.1-T2V-14B,仅需 1/2500 的数据集、1/200 的训练成本和 1/5 的推理步骤,就超越了 Wan-I2V-14B 模型的性能。
更厉害的是,Wan-I2V 只能进行图像到视频的生成,而 PUSA 模型还支持包括首尾帧生成、视频扩展、文生视频等功能
代码和模型都已经开源啦,完整介绍可以看PUSA 项目官网~
商业转载请联系三花微信公众号获得授权,非商业转载请注明本文出处及文章链接,您可以自由地在任何媒体以任何形式复制和分发作品,也可以修改和创作,但是分发衍生作品时必须采用相同的许可协议。
本文采用 CC BY-NC-SA 4.0 - 非商业性使用 - 相同方式共享 4.0 国际 进行许可。