simple-evals:OpenAI 开源评估 LLM 的轻量级库
OpenAI 开源这个库是为了公开透明地展示他们最新模型(从gpt-4-turbo-2024-04-09开始)发布的准确度数据。
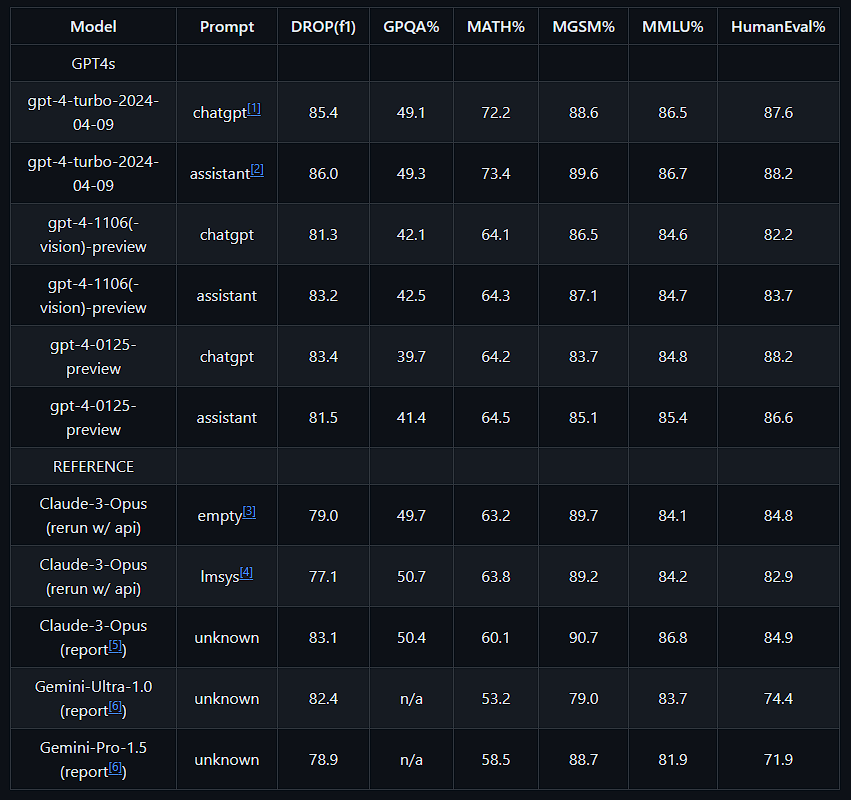
OpenAI 开源这个库是为了公开透明地展示他们最新模型(从gpt-4-turbo-2024-04-09开始)发布的准确度数据。
评估方法对提示非常敏感,而且近期的出版物和库中使用的公式存在显著差异。
这个库特别强调零次学习(zero-shot)和思维链(chain-of-thought)设置,使用简单的指令,如“解决以下多项选择问题”,认为这种提示技术更能反映模型在实际使用中的性能。
目前,该仓库包含以下评估:
- MMLU:测量大规模多任务语言理解
- MATH:使用MATH数据集测量数学问题解决能力
- GPQA:一个研究生级别的Google-proof Q&A基准测试
- DROP:需要对段落进行离散推理的阅读理解基准测试
- MGSM:多语言小学数学基准(MGSM),语言模型是多语言思维链推理者
- HumanEval:在代码上训练的大型语言模型评估
商业转载请联系三花微信公众号获得授权,非商业转载请注明本文出处及文章链接,您可以自由地在任何媒体以任何形式复制和分发作品,也可以修改和创作,但是分发衍生作品时必须采用相同的许可协议。
本文采用 CC BY-NC-SA 4.0 - 非商业性使用 - 相同方式共享 4.0 国际 进行许可。